大模型“价格屠夫”DeepSeek再次发起大降价。
近日该公司宣布,其API输入费用调整为0.1元/百万tokens,输出2元/百万tokens。这意味着,大模型API价格再降低一个数量级。
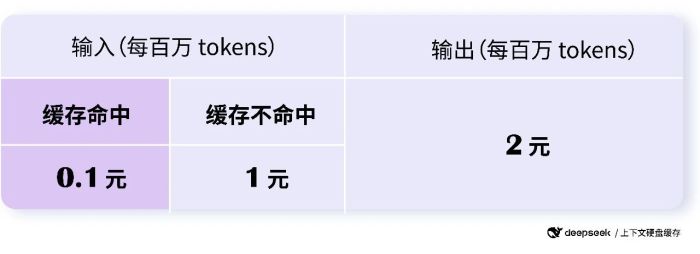
图源:DeepSeek
究其降价原因,DeepSeek解释称,在大模型API的使用场景中,用户输入有相当比例是重复的。例如用户的提示词往往有一些重复引用的部分,抑或在多轮对话中,每一轮都要将前几轮的内容重复输入。
针对上述问题,DeepSeek启用上下文硬盘缓存技术的解决方案,把预计未来会重复使用的内容,缓存在分布式的硬盘阵列中。如果输入存在重复,则重复的部分只需要从缓存读取,无需计算。这也是本次大模型降价的原因。
DeepSeek指出,上下文硬盘缓存技术不仅能降低服务延迟,还可大幅削减最终的使用成本。
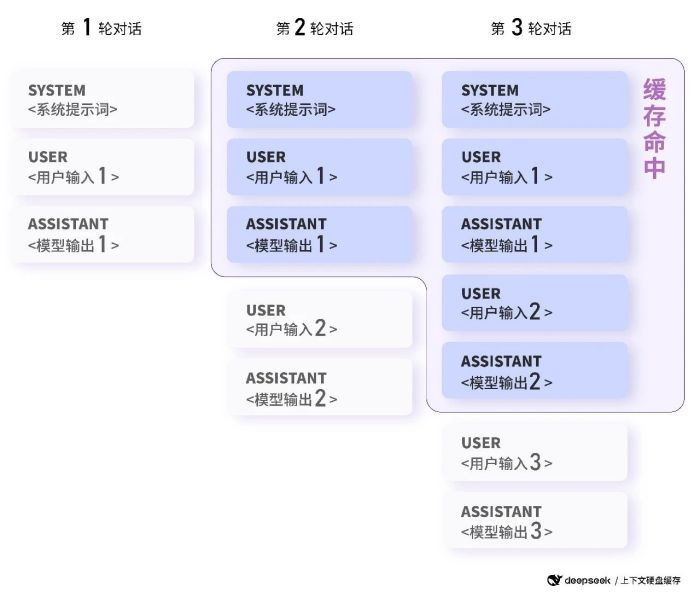
图源:DeepSeek
DeepSeek也是全球第一家在API服务中大范围采用硬盘缓存的大模型厂商。这主要得益于DeepSeekV2提出的MLA结构——在提高模型效果的同时,大幅压缩上下文KVCache的大小,使得存储所需要的传输带宽和存储容量均大幅减少,因此可以缓存到低成本的硬盘上。
此外,DeepSeekAPI服务按照每天1万亿的容量进行设计,对用户均不限流、不限并发。
这并非该公司首次降价。今年5月以来,搅局者DeepSeek即率先发起API价格战。
早在4月25日,DeepSeek将API定价在1元/百万输入tokens,2元/百万输出tokens。5月6日,DeepSeek发布开源MoE模型,参数更低,能力更强,API降至1元/百万输入tokens,2元/百万输出tokens,该价格约为GPT 4 Turbo的百分之一。
这一降价动作迅速引发全行业的响应,智谱AI 、火山引擎、百度、腾讯、阿里云等纷纷宣布降价。
其中,阿里云宣布通义千问核心模型Qwen-Long降幅为97%,降价后仅为0.0005元/千tokens。百度和腾讯则相继宣布部分大模型免费。
而在海外,OpenAI的GPT 4o发布后宣布免费使用,API调用价格减半。
值得关注的是,5月15日的火山引擎的一场活动上,火山引擎总裁谭待宣布豆包通用模型pro-32k定价只有0.0008元/千tokens,市面上同规格模型的定价一般为0.12元/千 tokens,是豆包模型价格的150倍。豆包模型的定价比行业便宜99.3%,带动大模型价格进入“厘时代”。
谭待指出,降低成本是推动大模型快进到“价值创造阶段”的关键因素之一,大模型卷价格将助力企业以更低成本加速业务创新。
彼时,一名火山引擎内部人士告诉界面新闻:“豆包大模型降价的真实原因在于,大模型在企业端的应用还未发展起来,场景太少。”他指出,虽然行业在讨论用AI大模型重构业务,但在日常工作生活里很少能感受到大模型能力的落地,“降价本质上是降低使用门槛。”
从降幅来看,输入降价幅度普遍高于输出降价幅度。大多数降价产品为轻量化模型版本,仅适用于频次不高、推理量不大、任务简单的中小企业、个人开发者短期使用。
整体来说,大模型仍然处于市场培育阶段。目前API降价更多是大模型厂商的获客策略,以让更多企业接入到自己的业务场景中,推动大模型在各行各业的应用落地,进一步加速商业化。该举措有助于吸引开发者和合作伙伴,快速建立生态,也为各个领域的创新应用提供了更广阔的空间。
降价或免费都是为了让更多企业和开发者能快速用上大模型,毕竟,让更多人参与进来是行业获得发展的前提。
然而,仅靠API生意显然难以完成大模型商业化的闭环。“没有一家大模型公司靠卖API活着。”此前一名关注大模型行业的FA(财务顾问)对界面新闻记者表示。
猎豹移动董事长兼CEO傅盛也认为,大降价基本宣告了大模型创业公司必须寻找新的商业模式。降得最凶的都是有云服务的大公司,通过大模型来获取云客户,“羊毛出在猪身上,降得起”,而大模型创业公司没有这样的生态,必须另寻商业模式。
与首轮降价所不同,面对此次DeepSeek发起的价格战,目前一众大模型公司尚未有跟进动作,也少有发表相关评论。但再次降价表明大模型的普惠时代正在到来,垂直应用生态有望进一步繁荣。




